From Monolith to Mosaic: How Composable AI is Redefining Enterprise Value
Enterprise AI is shifting from giant, costly models to efficient, specialized Small Language Models (SLMs) working in teams. This composable approach boosts accuracy, cuts costs, enhances privacy, and enables on-premise deployment—transforming AI into a competitive advantage for 2026 and beyond.


For the last few years, the world of enterprise AI has been dominated by giants. We’ve been captivated by monolithic, general-purpose Large Language Models (LLMs)—digital titans capable of seemingly anything. But as businesses move from wide-eyed experimentation to the hard reality of production, the cracks in this "bigger is better" philosophy are starting to show. The age of the AI monolith is ending.
Welcome to the era of the specialist.
The next wave of value in enterprise AI won’t come from a single, all-powerful model. It will be driven by a radical shift towards composable, multi-agent systems—intelligent teams of lean, specialized, and cost-effective AI components working in concert. This isn't a far-off prediction; it's a tectonic shift happening right now, propelled by three powerful technological forces that are rewriting the rules of AI architecture and economics.
First, Small Language Models (SLMs) have come of age. Once seen as the junior varsity team, these compact models are now outperforming their larger cousins on critical business tasks, all at a fraction of the cost.
Second, intelligent orchestration is providing the brain and nervous system for these new AI teams. Smart routing models and dedicated reasoning engines are directing traffic, ensuring the right agent tackles the right problem, and reserving the expensive, high-powered models for only the most complex challenges.
Finally, the tools for specialization have been democratized. Advanced, accessible fine-tuning and evaluation platforms are empowering companies to turn their proprietary data from a dusty asset into a powerful competitive weapon, creating hyper-accurate AI agents that know their business inside and out.
For leaders and investors, this is more than a technical upgrade—it's a complete restructuring of the AI value chain. The competitive edge is no longer about accessing the biggest model, but about mastering the art of building and managing a sophisticated "society of specialists."
This is your playbook for navigating that shift. Here are four data-backed strategic bets that will define enterprise AI in 2026 and beyond.
The Age of AI Dinosaurs
Why Giant Models Are Hitting a Wall
The first wave of GenAI adoption was a gold rush, sparked by the jaw-dropping, do-anything capabilities of frontier LLMs from labs like OpenAI, Google, and Anthropic. Companies invested heavily, with 67% of AI decision-makers planning to increase their genAI budgets in 2025.
The strategy was simple: point a giant, all-purpose AI "starship" at every problem. While impressive, this is massive overkill for most business tasks. Using a trillion-parameter model for routine enterprise workflows is like using a supercomputer to do basic math—powerful, but incredibly inefficient.
The economics simply don't scale. Per-token API pricing leads to unpredictable, spiraling costs. Training these models from scratch is a non-starter for most, requiring millions of dollars and months of GPU time. This creates vendor lock-in and puts a critical piece of the tech stack in the hands of a few giant providers.
As the initial "wow factor" fades, a new set of enterprise demands has emerged: privacy, accuracy, and cost-effectiveness. Sending sensitive data to third-party APIs is a non-starter for regulated industries like finance and healthcare. And the infamous "hallucinations" and biases of models trained on the wild west of the internet pose a major risk for any business-critical application.
This is the tipping point. Gartner's 2025 Hype Cycle places GenAI squarely in the "Trough of Disillusionment," as less than 30% of AI leaders report that their CEOs are happy with the ROI on their AI spend. The high Total Cost of Ownership (TCO) of the monolithic approach is economically and operationally unsustainable. The market is hungry for an alternative, and a new, more composable architecture is ready to step in.
Meet the Specialists
How Small AI Models Are Winning the Enterprise
The engine of this new paradigm is the Small Language Model (SLM). Far from being "LLMs-lite," these specialized models are proving that in the world of enterprise AI, smarter beats bigger.

Closing the Capability Gap (and Then Some)
SLMs (typically models with under 30 billion parameters) are using advanced techniques like knowledge distillation and quantization to pack a serious punch in a small package. But here’s the game-changer: when fine-tuned on high-quality, domain-specific data, SLMs can match or even outperform giant generalist models on targeted tasks.
Why? Because they become true experts. A model trained on the entire internet knows a little about everything, but an SLM trained on your company's legal documents knows your contracts better than anyone. We're already seeing this play out:
- In Healthcare: The Diabetica-7B model, focused on diabetes, achieved higher accuracy than both GPT-4 and Claude-3.5 on the same task.
- In Reasoning: Microsoft's Phi models proved that with the right "textbook-quality" data, even small models can develop the complex reasoning skills once thought to be exclusive to massive LLMs.
The Unbeatable Economics of SLMs
While the performance is compelling, the economics are transformative. SLMs are:
- Dramatically Cheaper: Training an SLM can be up to 1000x less expensive than an LLM, with operational cost reductions as high as 90%.
- Faster and More Efficient: Their small size means lightning-fast, sub-second response times, which is critical for real-time applications like customer service bots or fraud detection.
- Secure and Private: SLMs can be deployed on-premise or even on edge devices (like a smartphone or factory sensor), keeping your most sensitive data safely behind your firewall. This is a massive win for data sovereignty and compliance.
This table breaks down the strategic trade-offs:
Table 1: SLM vs. LLM - A Comparative Enterprise Scorecard
| Dimension | Small Language Models (SLMs) | Large Language Models (LLMs) |
|---|---|---|
| TCO (Training & Inference) | Low. Significantly lower computational, energy, and financial costs. Training can be up to 1000x cheaper. | High to Very High. Requires massive GPU clusters and sustained, high operational expenditure, especially for API-based models at scale. |
| Inference Latency | Low. Smaller size enables sub-second response times, ideal for real-time applications. | High. Larger models require more processing time, making them less suitable for latency-sensitive tasks without specialized hardware. |
| Data Privacy & Security | Excellent. Can be deployed on-premise or on-device, keeping sensitive data within the organization's control and compliant with regulations like GDPR/HIPAA. | Moderate to Low. API-based models require sending data to third-party vendors, posing potential privacy and security risks. |
| Customization & Specialization | Excellent. Designed for efficient fine-tuning on domain-specific data, leading to high accuracy on targeted tasks. | Good but Costly. Can be fine-tuned, but the process is resource-intensive. Often used as a general-purpose model. |
| General Knowledge Breadth | Limited. Knowledge is confined to their training and fine-tuning data; they lack broad, general-world understanding. | Excellent. Trained on vast internet-scale datasets, providing a comprehensive base of general knowledge. |
| Complex Reasoning | Limited (but improving). Generally less adept at multi-step, complex reasoning unless specifically designed for it (e.g., Phi-3). | Excellent. The primary strength of frontier models is their ability to handle complex, nuanced, and multi-step reasoning tasks. |
| Ideal Deployment Environment | On-Premise, Private Cloud, Edge Devices. Ideal for applications requiring data sovereignty, low latency, and offline capabilities. | Public Cloud. Typically accessed via APIs due to their massive infrastructure requirements. |

The Specialists Have Arrived
The market is already flooded with powerful, production-ready SLMs. This isn't a future trend; it's a vibrant ecosystem you can tap into today.
Table 2: Leading Small Language Models of 2025 - Performance and Enterprise Suitability
| Model Name | Developer | Parameter Size | Key Features | Best-Fit Enterprise Use Cases |
|---|---|---|---|---|
| Llama 3.3 8B | Meta | 8 Billion | New state-of-the-art for its size class as of late 2025. Enhanced reasoning, coding, and multilingual support over previous versions. Large open-source ecosystem. | Versatile all-rounder; AI chatbots; writing assistants; internal knowledge tools. |
| Phi-3-mini/small | Microsoft | 3.8B / 7B | Exceptional reasoning and logic for its size; trained on high-quality synthetic data; 128K context window variant available. | On-device AI; logic-intensive tasks; private deployments; educational tools. |
| Mistral 7B / NeMo 12B | Mistral AI | 7B / 12B | Highly flexible and easily fine-tunable; strong function calling and coding performance; Apache 2.0 license. | Custom domain-specific applications; AI agents; code generation; RAG systems. |
| Qwen3 Family (0.6B - 235B) | Alibaba | SLM variants (0.6B - 32B); LLM variants (30B & 235B MoE) | Spans the full spectrum from SLMs to LLMs, supporting a heterogeneous model strategy. Extensive multilingual support (119 languages). Introduced a dual-mode capability, initially as a hybrid model with a toggle for "thinking" (deep reasoning) and "non-thinking" (fast response) modes. This was later updated to separate, dedicated Instruct and Thinking models to maximize performance. | Non-thinking mode: Global applications, multilingual customer support, content localization. Thinking mode: Complex agentic workflows, financial analysis, scientific research, and advanced coding tasks requiring deep, step-by-step reasoning. |
| Gemma 2 (2B - 9B) | 2B / 9B | Built on Gemini research; optimized for on-device and desktop deployment; strong integration with Google Cloud and Hugging Face. | Privacy-first AI tools; summarization and Q&A on local machines; Android applications. | |
| Falcon-H1 Family (0.5B - 34B) | Technology Innovation Institute (TII) | SLM variants (0.5B, 1.5B, 3B, 7B); LLM variant (34B) | Demonstrates an innovative hybrid architecture (Transformer + SSM) for high efficiency and performance. Outperforms models twice its size (e.g., 0.5B rivals 7B models). Supports long context (up to 256K tokens) and 18 languages. Permissive open-source license. | High-performance, low-latency applications; on-premise and edge deployments; long-document processing; cost-sensitive workloads requiring strong reasoning. |
Success Stories from the Field
This shift is already creating massive value.
- JPMorgan Chase's COiN platform uses a specialized AI to review complex loan agreements. The result? It saves an astonishing 360,000 hours of legal work every year, cut operational costs by 30%, and reduced compliance errors by 80%.
- Indian real estate platform NoBroker built its own SLMs for customer service, training a highly effective model on just "10 hours of recording" data to handle multiple languages for tasks like sentiment analysis.
- Even Microsoft uses SLMs internally to manage its own Azure cloud supply chain, finding that fine-tuned models like Phi-3 and Llama 3 delivered higher accuracy and faster responses than giant, general-purpose LLMs for the task.

The lesson is clear: competitive advantage is no longer about accessing the biggest model. It's about your ability to turn your unique data into a fleet of specialized, efficient AI experts.
The AI Team's Nervous System
Reasoning and Routing
A collection of specialist models is powerful, but it's not a system. To make them work together, you need an architectural fabric—a brain and a nervous system. This is where compact reasoning models and intelligent routers come in, unbundling the functions of a giant LLM into a smarter, more efficient stack.
A Dedicated "Brain" for Complex Thinking
Standard AI models are great at pattern matching, but they can struggle with the kind of deep, multi-step reasoning needed for complex planning. A new class of compact, hyper-efficient reasoning models is emerging to solve this.
The Hierarchical Reasoning Model (HRM), for example, is a tiny 27-million-parameter model—a fraction of the size of an SLM—that can solve extreme Sudoku puzzles and find optimal paths in large mazes, tasks where even giant LLMs fail completely. It does this by separating abstract planning from detailed calculation, much like the human brain.
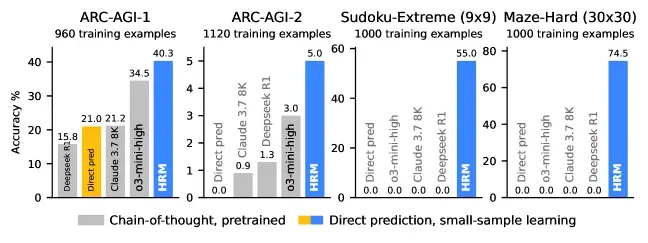
The strategic implication is huge: you can now have a dedicated, lightweight "planning agent" in your system that handles the heavy cognitive lifting without the cost and latency of a frontier LLM.
The Intelligent Switchboard for Optimal Efficiency
In a system with a diverse portfolio of models, an intelligent router is the essential nervous system. It acts as a smart switchboard, inspecting every incoming query and sending it to the best model for the job.
Its primary function is cost optimization. Simple, high-volume questions get sent to cheap, fast SLMs. Only the most complex, high-value problems get escalated to the expensive frontier models. The savings are staggering:
- The open-source RouteLLM framework has demonstrated production savings of up to 85% while maintaining near-GPT-4 quality.
- An AWS analysis showed how a simple routing strategy—sending math questions to a powerful model and history questions to a cheaper one—could perfectly balance cost and quality.
This combination of specialized agents, a dedicated reasoner, and an intelligent router creates a symbiotic AI fabric. It's a "Lego-like" system that is not only cheaper and faster but also more agile, debuggable, and easier to adapt than a single, monolithic black box.
The Cambrian Explosion
Building and Scaling AI Teams
The convergence of SLMs and intelligent orchestration enables the ultimate goal: the multi-agent system (MAS). Here, complex business processes are broken down and delegated to a team of collaborating AI agents, each with a specific role and expertise. This isn't science fiction; it's the new frontier of enterprise automation.

Why AI Teams Outperform Lone Wolves
This approach mirrors how expert human teams work, and the performance gains are dramatic. Gartner predicts that by 2028, one-third of all enterprise software applications will include agentic AI, up from less than 1% in 2024.
The data backs this up. An AWS study found that a multi-agent architecture achieved a 90% success rate on complex tasks, while a single-agent system using the same tools and models scored as low as 53% on the same problems.
Your Toolkit for Building Agentic Systems
A vibrant ecosystem of frameworks has emerged to help build and manage these AI teams.
Table 3: Leading Multi-Agent Frameworks - A Feature Comparison
| Framework | Primary Architecture | Key Features | Ideal Use Case |
|---|---|---|---|
| Microsoft AutoGen | Conversational, Layered | Asynchronous messaging, debugging tools, no-code studio, scalable agent networks. | Building complex, conversational multi-agent applications and research prototypes. |
| CrewAI | Role-Based Orchestration | Defines agents with roles/goals, supports sequential and hierarchical processes, model-agnostic. | Automating structured business workflows that mimic human team collaboration (e.g., research and reporting). |
| LangGraph | Graph-Based | Represents workflows as nodes and edges, enables cycles and conditional logic, robust state management. | Non-linear, dynamic processes that require agents to loop back, make choices, or wait for human-in-the-loop input. |
| Agno (Phidata) | Full-Stack Agentic | Natively multi-modal, memory and reasoning as first-class citizens, high-performance design. | Building production-grade, scalable agentic systems with complex memory and reasoning requirements. |
Major cloud providers like Google and AWS are also rolling out enterprise-grade platforms like Vertex AI Agent Builder to manage the entire lifecycle of these systems, simplifying the path to production.
The New Scalability Challenge
Of course, managing a team of autonomous AI agents introduces new challenges, similar to the shift from monoliths to microservices in software engineering. Key hurdles include ensuring reliable communication, managing conflicts between agents with different goals, and the immense difficulty of debugging a distributed, non-deterministic system. Furthermore, a lack of universal standards currently creates "walled gardens" between different frameworks.
The Compelling Economics of AI Teams
Despite the complexity, the economic case is undeniable. By avoiding the use of your most expensive AI model for every single step of a process, the aggregate cost plummets.
This TCO model for a customer support workflow tells the story:
Table 4: TCO Comparison - Monolithic LLM vs. Multi-Agent SLM Architecture
Scenario: Processing 1 Million Customer Support Inquiries per Month
| Cost Component | Monolithic LLM Architecture | Multi-Agent SLM Architecture |
|---|---|---|
| Description | All 1M inquiries are processed by a single, expensive frontier LLM (e.g., Claude 3.5 Sonnet). | A router sends 80% of inquiries to a cheap SLM (e.g., Llama 3 8B), 15% to a mid-tier model (e.g., Mistral Small), and 5% to the frontier LLM. |
| Model Inference Cost | $10,500. (Assumes 150 input/300 output tokens per query. 1M queries x 450 tokens/query = 450M tokens. Cost: $3/M input, $15/M output. Blended rate ~ $11/M. 450M tokens x $11/M = $4,950 input + $5,550 output (approx)) | $2,115. (800k to SLM @ ~ $0.5/M = $360. 150k to Mid-Tier @ ~ $3/M = $405. 50k to LLM @ ~ $11/M = $525. Total = $1,290 + router costs) |
| Orchestration/Routing Layer Cost | $0. (No router needed). | ~ $825. (Router processes 1M queries. Assumes a fast, cheap model like Titan Express. 150 input tokens/query = 150M tokens @ $0.2/M = $30. Plus compute/platform costs). |
| Data/Tool API Calls | Assumed to be part of the LLM's internal process or a fixed cost. | Assumed to be similar, but potentially more efficient as tools are called by specialized agents. |
| Compute/Hosting Infrastructure | High. Requires enterprise-grade API subscription or massive on-premise cluster for a single large model. | Moderate. Requires hosting multiple smaller models and a router, which can be done on more modest on-premise hardware or a hybrid cloud setup. |
| Monitoring & Maintenance | Simpler. Monitor one model endpoint. | More Complex. Requires observability across multiple agents and their interactions, increasing operational overhead. |
| Estimated Monthly Operational Cost | ~$10,500+ (Primarily API costs) | ~$3,000 - $5,000 (Blended API, hosting, and operational costs) |
| Estimated Monthly Savings | - | ~50% - 70% |
Note: Token pricing based on data from industry analysis. This is a simplified model for illustrative purposes; actual TCO would include development, data management, and human oversight costs.
The Strategic Playbook
4 Strategic Bets for the Composable AI Era
So, how do you win in this new landscape? It requires moving beyond experimentation and making deliberate, data-backed bets on the architectures of the future.
Bet #1: Build a "Portfolio" of AI Models
The days of relying on a single LLM provider are over. The winning strategy is a heterogeneous portfolio of models—proprietary, open-source, large, and small—optimized for each task.
- Your Action Plan: Establish an internal catalog to benchmark different models against your specific business needs. Treat an intelligent routing layer as a core piece of infrastructure. And embrace a multi-vendor, multi-cloud ecosystem to avoid lock-in and maximize flexibility.
Demonstrates the significant cost savings of a multi-model routing strategy with a practical enterprise Total Cost of Ownership (TCO) model.
Bet #2: Make Fine-Tuning a Core Business Competency
As powerful base models become a commodity, your unique, proprietary data becomes your ultimate competitive advantage. The ability to specialize models with that data is the new frontier.
- Your Action Plan: Invest in the data annotation and curation tools needed to create high-quality training datasets. Build an in-house MLOps practice focused on efficient fine-tuning techniques. And, most importantly, implement a rigorous, continuous evaluation framework that tests models against real business KPIs, not just academic benchmarks.
Microsoft's internal case study showing fine-tuned Small Language Models (SLMs) achieving higher accuracy and faster responses than large LLMs for a complex supply chain application.
Bet #3: Move from Generating Content to Automating Action
The real prize isn't generating text; it's autonomously executing complex business processes. Multi-agent systems are the key to unlocking this "actionable AI."
- Your Action Plan: Start pilot projects with open-source agentic frameworks like CrewAI or AutoGen to build hands-on expertise. Identify high-value, multi-step workflows in your organization—like supply chain optimization or financial reporting—that are prime candidates for automation.
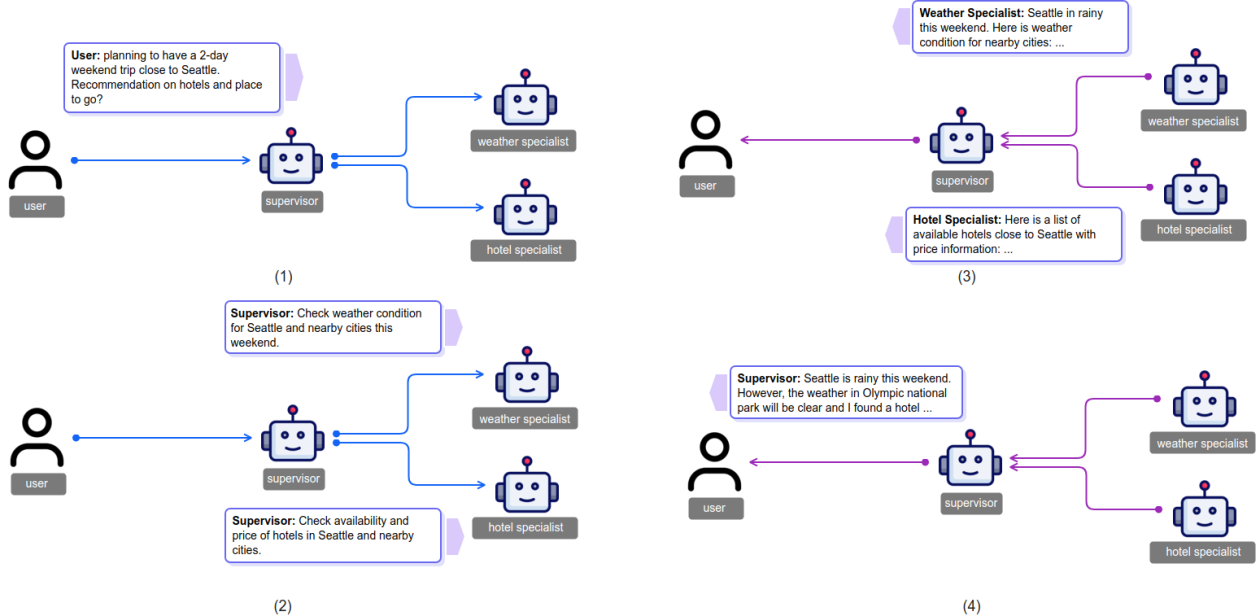
An empirical AWS study demonstrating that a multi-agent system achieved a 90% success rate on complex tasks, significantly outperforming a single-agent system.
Bet #4: Bring Your AI Home with On-Premise and Edge Deployments
The efficiency of SLMs finally makes it feasible to run powerful AI inside your own firewall or directly on devices at the edge. This is the ultimate solution for privacy, security, and low-latency applications.
- Your Action Plan: Segment your AI workloads. Identify tasks that involve sensitive data or require real-time responses and make them candidates for on-premise deployment. For these high-frequency tasks, the one-time capital expense on hardware can be far cheaper than the endless operational expense of API calls.

A real-world case study of a manufacturing client saving millions in fees by deploying a fine-tuned SLM on edge devices for anomaly detection.
The Future of AI is Composed, Not Commanded
The enterprise AI landscape is making a decisive shift away from the brute-force approach of monolithic LLMs and toward a more intelligent, sustainable, and pragmatic future. This new era will be defined by composition, specialization, and efficiency.
The technology is here. The economic incentives are undeniable. The early success stories are written.
The future of enterprise AI is not about buying a bigger hammer. It's about mastering the art of assembling a team of specialists, each with the perfect tool for the job. The organizations that thrive will be those that move decisively to build smarter, more efficient systems. The competitive advantage will belong not to those who simply use AI, but to those who master the art of composing it.
Key Takeaways
- Composable AI is overtaking monolithic models in the enterprise, offering better cost control, flexibility, and domain-specific accuracy.
- Small Language Models (SLMs) are now enterprise-ready: When fine-tuned on targeted data, they deliver results often rivaling or surpassing giant LLMs in specialized tasks—at a fraction of the cost.
- Multi-agent systems and orchestration frameworks enable teams of specialized models to collaborate, making AI-driven workflows more efficient, adaptable, and easier to manage.
- Significant TCO and operational savings: Intelligent routing and modular model deployment can cut AI operational costs by up to 70% while maintaining or even improving quality.
- Success in the GenAI era relies on building a diverse portfolio of models, investing in fine-tuning, and prioritizing on-premise or edge deployment for privacy and latency.
- Early adopters are already realizing value, with major organizations reporting significant gains in efficiency, compliance, and competitive advantage.



