InfiniBand: The King of AI Networking and the Walls of its Walled Garden
For over two decades, InfiniBand has powered the fastest AI clusters through native lossless design, RDMA, and in-network computing—making it the performance king. Yet, NVIDIA’s tight integration and high costs have hyperscalers seeking open, Ethernet-based alternatives.


Welcome back to our series on the future of AI networking! In our first post, we established why the network is the single most critical component of a modern AI factory and how the unique, punishing traffic patterns of AI workloads can bring traditional networks to their knees.
Now, it's time to meet the reigning champion of this demanding domain: InfiniBand.
For more than two decades, if you were building a world-class supercomputer or a serious, large-scale AI training cluster, the choice was simple. You used InfiniBand. Its name is synonymous with the absolute pinnacle of performance. It was born for this job.
But as the AI gold rush accelerates, the very things that make InfiniBand so powerful are causing the industry's biggest players to search for an escape route. Let's take a deep dive into the king's architecture and explore the gilded walls of its incredible, yet confining, garden.
A Fabric Born for Speed: Architecture and Native RDMA
You can't understand InfiniBand's dominance without first understanding a key philosophical difference in its design. Traditional Ethernet was built to be a general-purpose, "best-effort" network. It's inherently lossy, meaning it handles traffic jams by dropping packets and relying on software higher up the stack (like TCP) to notice the loss and resend the data. This process is a killer for performance, introducing unacceptable latency and jitter for tightly synchronized AI workloads.
InfiniBand was designed from the ground up to be lossless. It achieves this through a simple, elegant mechanism: credit-based link-layer flow control.
Think of it like a meticulous shipping manager. Before a sender transmits a single packet, the receiver must explicitly grant it "credits," confirming it has buffer space available. No credits? No data is sent. This prevents network switches from ever being overrun, eliminating packet loss at the most fundamental level.
This lossless foundation makes InfiniBand the perfect vehicle for Remote Direct Memory Access (RDMA). RDMA is a technology that allows the network card in one server to write data directly into the memory of another server, completely bypassing the main CPUs and operating systems on both ends. This "kernel bypass" slashes through layers of software overhead, enabling the mind-bogglingly low latencies—often below a single microsecond—that AI applications crave.
While RDMA exists on Ethernet (as we'll explore in our next post), InfiniBand implements it natively. Its network cards, called Host Channel Adapters (HCAs), are built for this one purpose, giving it an undisputed home-field advantage on raw performance.
The Secret Weapon: When the Network Becomes the Computer
Beyond its raw speed, the NVIDIA InfiniBand ecosystem has a killer feature that has been a key differentiator for years: in-network computing. The most powerful example of this is a technology called SHARP (Scalable Hierarchical Aggregation and Reduction Protocol).
To understand the genius of SHARP, consider a critical step in AI training called an All-Reduce operation. This is where every GPU in the cluster needs to share its latest calculations (gradients) with every other GPU, average them all together, and update its model. In a traditional network, this creates a data traffic explosion.
With SHARP, the network switches themselves become active participants in the math.
Imagine a hundred people needing to calculate the average of their results. The old way is for every person to shout their number to all 99 others. It's chaos. SHARP turns the network switch into a designated calculator. Each GPU sends its gradient data into the switch, which performs the reduction operation (like summing the values) on the switch hardware itself. The switch then forwards only the final, aggregated result.
This has a massive impact.
- It dramatically reduces the total volume of data crossing the network, alleviating congestion.
- It shortens the time for the entire operation, which directly reduces the all-important Job Completion Time (JCT).
SHARP transforms the network from a passive set of pipes into an active part of the computational fabric. It’s a powerful advantage and a high bar for any competitor to clear.
The Gilded Cage and the Perils of Proprietary Power
So, InfiniBand is a technical masterpiece. It's faster, more efficient, and has unique computational capabilities. Why, then, are the world's largest cloud providers desperately trying to replace it?
The answer has nothing to do with technology and everything to do with strategy and economics.
Following its acquisition of Mellanox, the original pioneer of InfiniBand, NVIDIA has become the sole, end-to-end provider of the entire InfiniBand ecosystem. They build the GPUs (H100, B200), the on-node interconnect (NVLink), the InfiniBand switches (Quantum), the DPUs (BlueField), and the software (CUDA).
This tight, vertical integration delivers undeniable, co-optimized performance. For customers who want a turnkey, record-breaking solution, the NVIDIA platform is incredibly compelling.
However, for a hyperscaler or large enterprise, this single-vendor ecosystem is a massive strategic risk. It creates the classic "vendor lock-in" scenario, where a customer becomes wholly dependent on one company's roadmap, supply chain, and pricing power. The biggest buyers of technology historically demand open, standards-based, multi-vendor ecosystems that ensure supply diversity, foster competition, and drive down costs.
The economic implications are stark.
- High CapEx: InfiniBand hardware—HCAs, switches, and even proprietary cables—comes at a significant price premium. One 2023 analysis estimated the per-node interconnect cost for an InfiniBand cluster at around $4,500, compared to just $2,800 for a comparable high-performance Ethernet setup.
- High OpEx: The pool of engineers with deep expertise in designing and managing InfiniBand fabrics is far smaller and more specialized than the vast global talent pool for Ethernet. This drives up personnel costs and makes hiring a challenge.
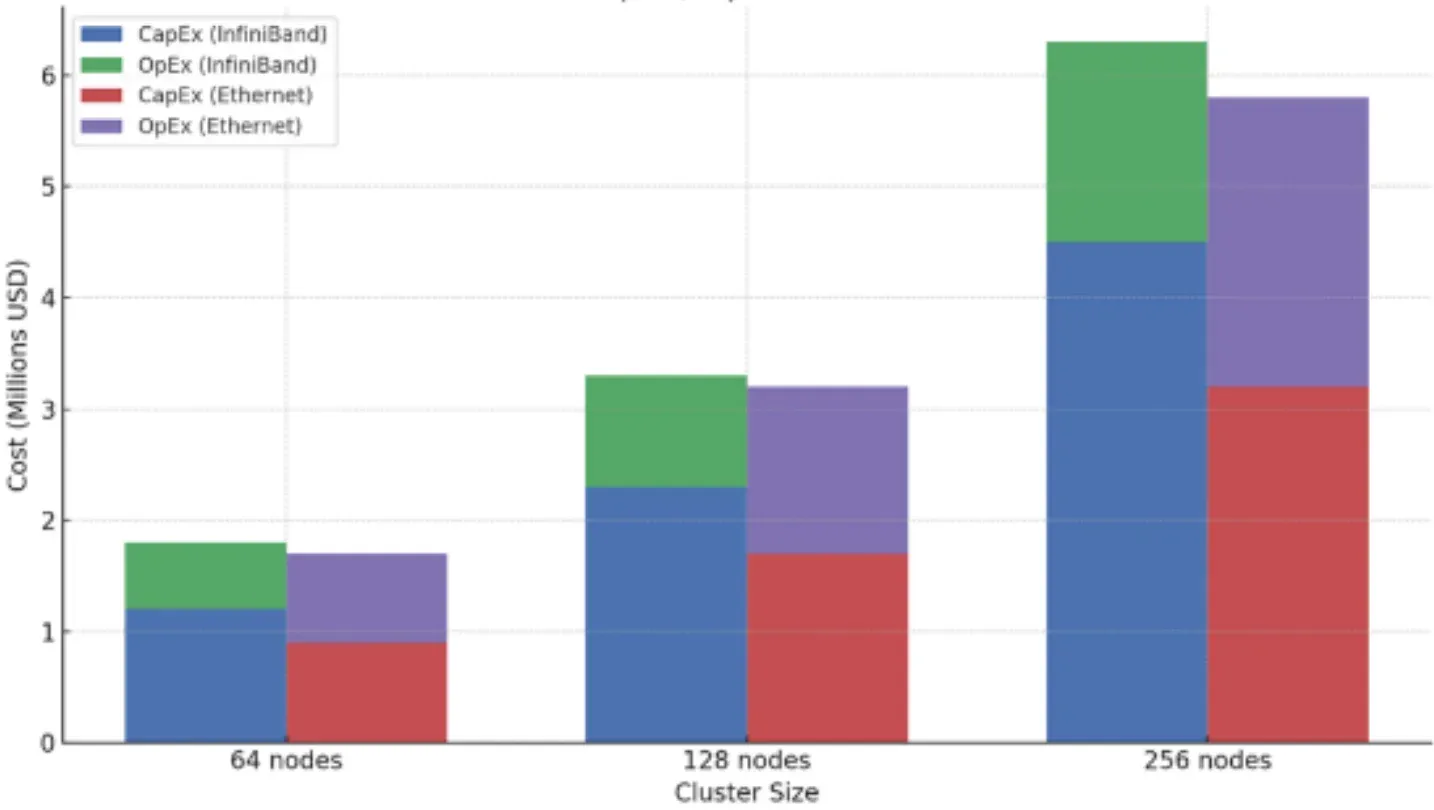
This is the central paradox of InfiniBand. Its greatest technical strength—the highly integrated, purpose-built design—has become its greatest strategic vulnerability. The market's immense desire to escape this "InfiniBand trap" has created a powerful vacuum, fueling an industry-wide revolution to build something better, something more open.
And that something is a completely transformed version of Ethernet.



